Scrapyとは
Scrapyはスクレイピング用のフレームワーク。
(比較)PythonのDjangoやRubyのRuby on RailsがWebアプリケーション用のフレームワーク
収集(クローリング)、加工(スクレイピング)、保存機能が揃っており、
Pythonでそれぞれのライブラリをつなぎ合わせた記述をすることなく、
それぞれの機能を使うことができる。
メリット:記述を整理した状態で、拡張しやすい。非同期処理が可能。
デメリット:慣れるのに時間がかかる。日本語の教材は限られている。
※Djangoなどでフレームワークという概念に触れていた方が理解しやすい。
学習順序
0.クローリング、スクレイピングの勉強
1.Scrapyの利用例が豊富な資料
Pythonクローリング&スクレイピングの6章
2.公式ドキュメントのBasic Conceptを読む。
詳細には説明されていないので、適宜追加で検索が必要。
その他
動画(Udemy):Scrapy: Powerful Web Scraping & Crawling with Python
書籍:Powerful Web Scraping & Crawling with Python
Scrapyは細かく役割分担がされている。
下記Scrapyの公式ドキュメント
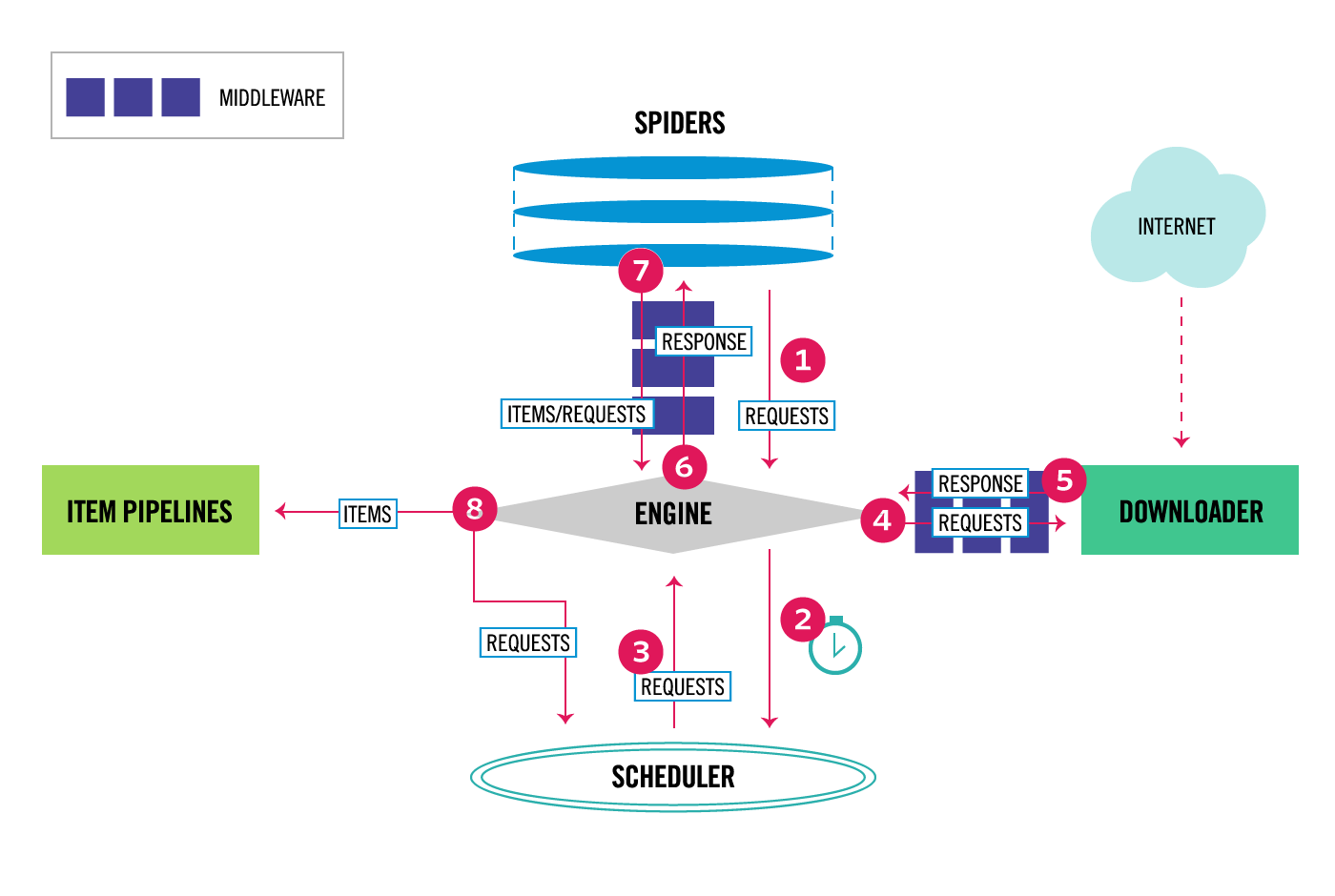
ScrapyEngine:実行エンジン。あまり意識しない。
Spider:Request内容やスクレイピングの詳細を記述することになる。最重要。
Downloader:ダウンロード機能。あまり意識しない。
ItemPipeline:Spiderから渡されたItemの処理(データ内容の確認、保存)
FeedExporter:Itemの保存。あまり意識しない。
簡単なガイド
環境を整える。
・関係ライブラリからのダウンロード
sudo apt-get install -y libssl-dev libffi-dev python3-dev
Scrapyのインストール
pip install scrapyscrapy startproject project名 directory名
作成されるファイル群
directory
|-project
| |-items.py:itemを定義するファイル
| |-pipelines.py:ItemPipelineを定義するファイル
| |-settings.py:設定ファイル
| |-spiders:Spiderを格納するディレクトリSpiderの作成 ・クローリング先の指定
start_urls, start_request
・スクレイピング
response.css(CSS セレクタ)やresponse.xpath(XPath)で抽出
・出力内容
yield scrapy.Request()でRequestを作成する
yield itemでItemを作成する
- Spiderの実行
プロジェクトディレクトリに入った状態で、
scrapy run spider